What is Data Vault?
Data Vault is a hybrid modeling methodology, that stands between the 3rd Normal Form and denormalized forms coming from Business Intelligence world; as a methodology, it’s therefore not constrained by specific tools or by technology-related choices (even if the sizing of the implementation should obviously be suitable).
This methodology was created by Dan Linstedt in the 90’s and the first implementations were made in the beginning of 2000’s; so it’s not something new; but this methodology suffers of a lack of adoption in Europe compared to US, despite its great values, because it’s mainly considered as a technology change rather as a focus on business considerations (objects and processes).
Technically speaking, it is obviously not a revolution in terms of implementation, as it keeps and conciliates the best of both worlds between the transactional approach and the decisional approach. As a dedicated methodology for Enterprise Datawarehousing (EDWH) modeling, the objective is to get a reliable vison of business objects in a whole organization, whatever the business areas or operational business processes that use these objects.
The benefits of Data Vault
This methodology offers multiple benefits:
- A better readability of the data model, as it is very similar to a business modeling, when considering the objects and their relationships. So, it is not really a surprise for Project Management and Contracting Authority who can quickly understand and validate the macro-model, as it’s not new for them, just being part of their everyday business.
- A reduced number of technical entities (except some additional structures enhancing raw data exploitation on the way out of the EDWH); only 3 entities are necessary to build the EDWH:
- Hubs: they stand for the business objects, identified by their Business Key (BK)
- Links: they establish the relationships between the business objects
- Satellites: they store all the attributes of the business objects, along with their history on all changes
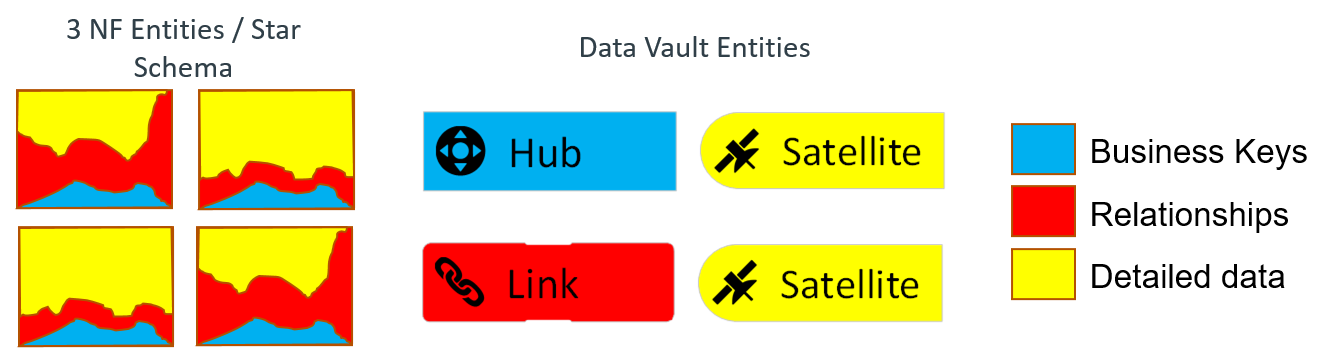
Fig.1: the different entities
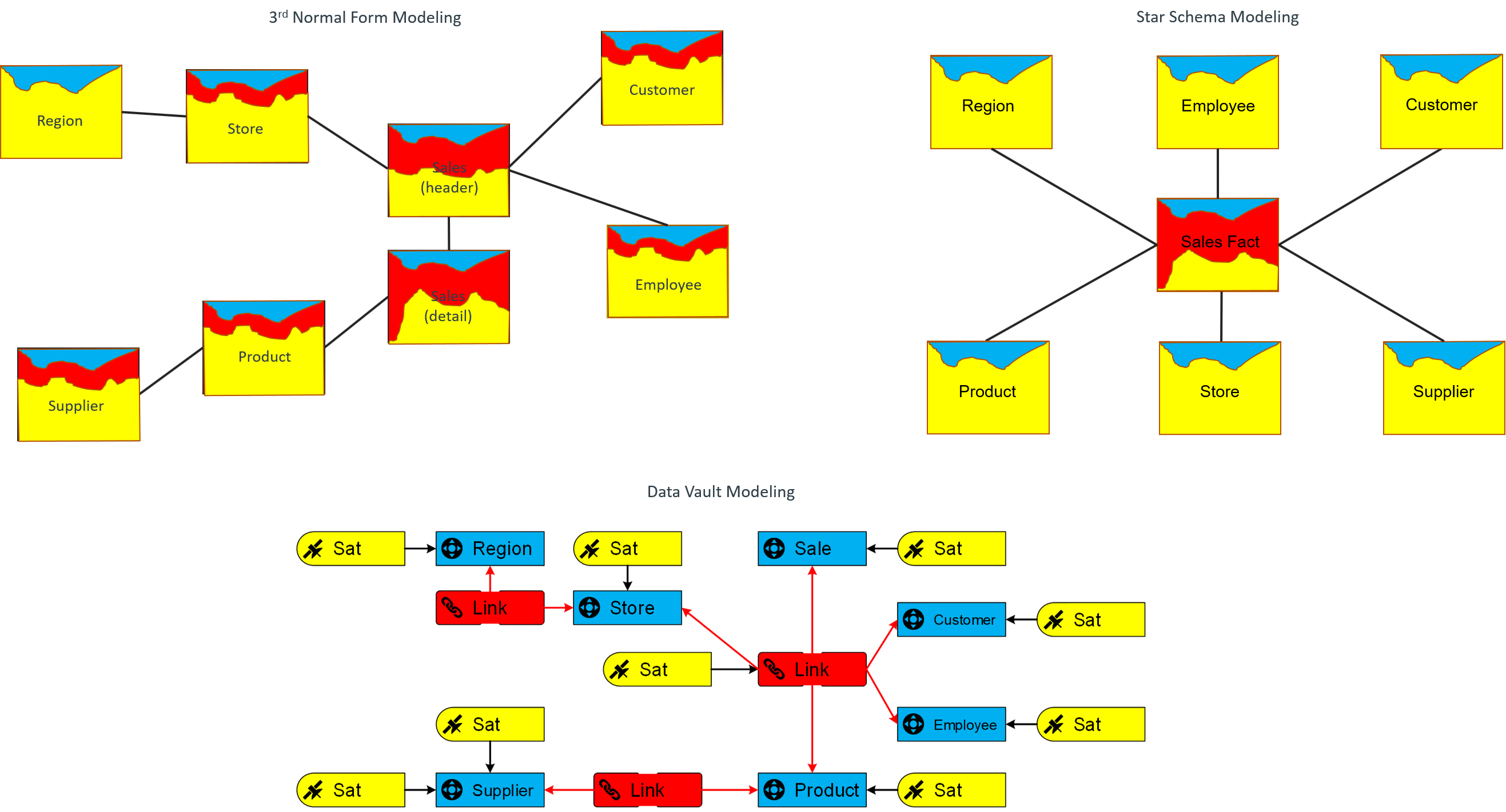
Fig.2: the different modeling types
- Refocusing on essential functions of an EDWH: storing, historizing, data traceability and data auditability.
- Simplified data ingestion processes due to the reduced number of data structures (with a normalization of data loading processes) and also by applying complex business rules on the way out of the EDWH, to Datamarts or other business-specific data stores.
- Preserving raw data, while being able to apply some simple, cross-entities rules (like DQ processes to correct / standardize data) for loading a “Business Vault” that stands “on the top” of the “Raw Data Vault”, being a business-oriented additional datastore.
- The ability to quickly ingest in the EDWH large data volume with high performance, without creating complex dependencies between different business areas or source systems.
- Scalability and flexibility of the model compared to a standard approach:
- It is easier to manage evolutions on attributes of objects or any change on a source system.
- It is easier to add new business objects without reengineering the model that was already built.
- It is easier to add a new source system for a business which is already part of the model, without rebuilding this model.
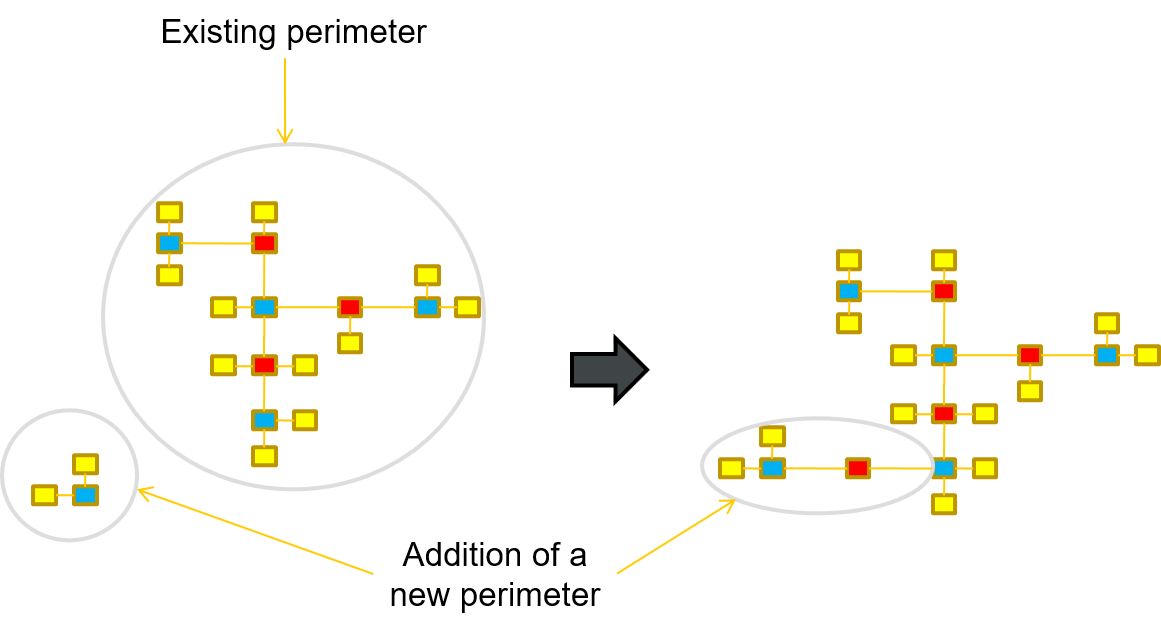
Fig.3: change with addition of a new object
To be continued here
Recent Comments