Qu’est-ce que Data Vault ?
Data Vault est une méthodologie de modélisation hybride entre la 3ème Forme Normale et les formes dénormalisées venant du monde décisionnel ; en tant que méthodologie, elle n’est donc absolument pas contrainte par des outils particuliers ou des choix de technologies (le dimensionnement de l’implémentation devant toujours évidemment être approprié).
Cette méthodologie a été créée par Dan Linstedt dans les années 1990 et les premières implémentations sont apparues au début des années 2000 ; ce n’est donc pas une nouveauté en tant que telle, mais cette méthodologie est peu répandue en Europe par rapport aux États-Unis et elle est souvent mal comprise car vue plutôt comme un changement de paradigme technologique au lieu de se concentrer sur les aspects métiers (objets et processus).
Technologiquement, elle n’a en effet rien de révolutionnaire en termes d’implémentation, puisqu’elle prend et concilie le meilleur de chacun des mondes entre l’approche transactionnelle et l’approche décisionnelle. S’agissant bien d’une méthodologie de modélisation dédiée au Datawarehousing d’Entreprise (ou EDWH : Enterprise Datawarehouse), l’objectif est de représenter correctement les objets métiers dans la globalité d’une organisation, ce quels que soient les secteurs métiers ou les différents processus pouvant les utiliser opérationnellement parlant.
Les bénéfices de Data Vault
Les bénéfices associés à cette méthodologie sont multiples :
- Une meilleure lisibilité du modèle, car très proche d’une modélisation métier, si l’on s’en tient aux différents objets impliqués et leurs relations. Ce n’est donc pas une surprise pour les MOEs et MOAs qui peuvent rapidement valider la compréhension et la validité d’un tel macro-modèle.
- Un nombre d’entités techniques très réduit ; en dehors de certaines structures complémentaires visant à accélérer l’exploitabilité des données en sortie de l’EDWH, seules 3 entités sont nécessaires :
- Les Hubs : ils portent les objets métiers représentés par leur clé métier (ou BK : Business Key)
- Les Links : ils portent les relations entre les différents objets métiers.
- Les Satellites : ils contiennent l’ensemble des attributs des objets métiers, ainsi que l’historique de leurs évolutions.
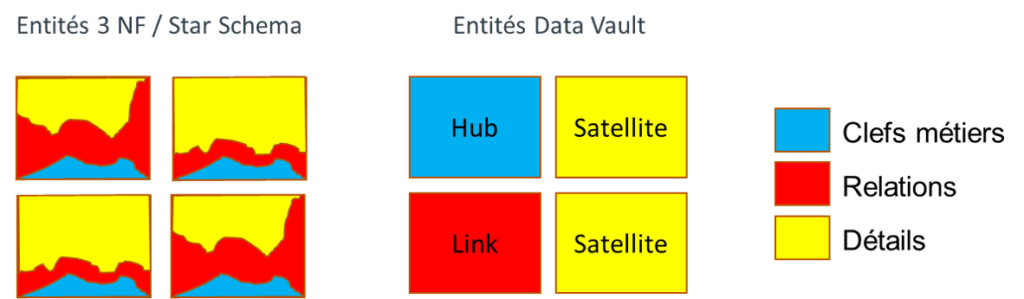
Fig.1: les différentes entités
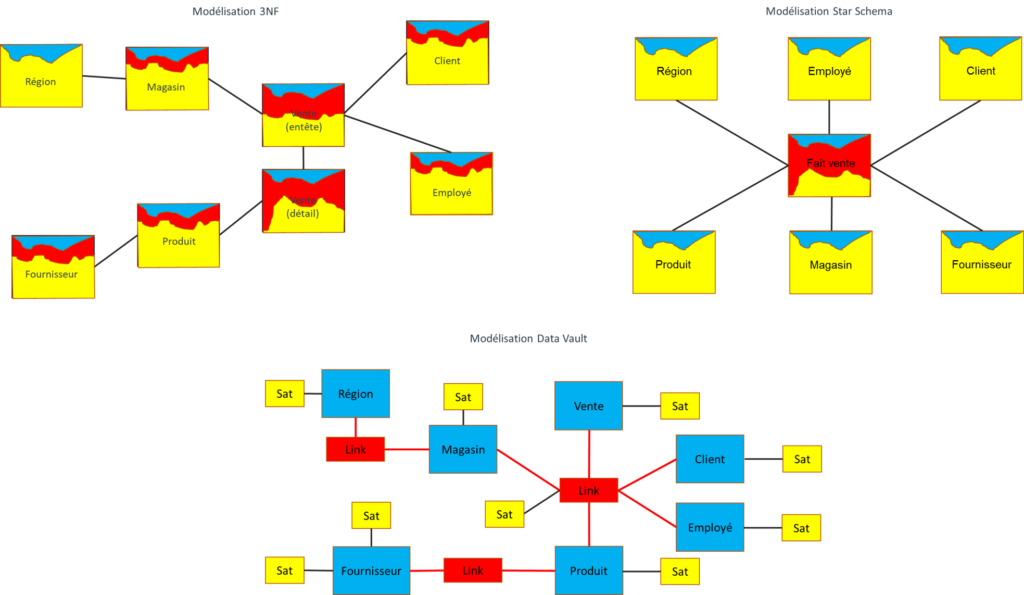
Fig.2: les différentes modélisations
- Le recentrage sur les fonctions primordiales d’un EDWH : stockage, historisation, traçabilité et auditabilité des données.
- La simplification des processus d’ingestion de la donnée du fait d’un nombre de structures réduit (et donc une normalisation des traitements d’alimentation) ainsi que par l’application des règles métiers complexes en sortie de l’EDWH, vers les Datamarts ou autres silos métiers.
- La conservation de la donnée brute, tout en gardant la possibilité d’appliquer certaines règles transverses et simples (comme des processus DQM pour redresser / standardiser la donnée) en vue d’une alimentation d’un « Business Data Vault » qui se positionne « au-dessus » en complément du « Raw Data Vault ».
- La possibilité d’absorber rapidement dans l’EDWH des volumes de données importants avec des performances élevées, sans créer de dépendances complexes entre différents métiers et systèmes sources.
- L’évolutivité du modèle par rapport à une approche classique :
- Il est plus facile de faire évoluer les attributs d’un objet ou tout changement d’un système source
- Il est plus facile de rajouter de nouveaux objets métiers sans remise en cause du modèle déjà implémenté.
- Il est plus facile de rajouter un nouveau système source pour un objet métier qui est déjà inclus, sans remise en cause du modèle déjà en place.
 Fig.3: évolution avec ajout d’un nouvel objet
Fig.3: évolution avec ajout d’un nouvel objet
Lire la suite ici
Commentaires récents